wgetコマンドでウェブサイトをサクッと丸ごとダウンロード!
- 2019.07.21
- テクニカルメモ

何年か前に少しやっていたブログ(WordPress)。もう更新することもないだろうし、サーバーのレンタル料金も勿体ないので閉じることに。
50記事ほどしかないとはいえ、当時の自分を思い出せる貴重な記録なので、どうにか残せないかと考えたところ、「丸ごと持ってきて手元に置いておこう」と決めました。
方法としては・・・
- 各記事・ページをPDF保存 → ちょっと面倒
- Mac内にMAMP(Apache, MySQL, PHP)環境を構築して再現 → 残すだけの目的にしては少々大げさ過ぎる
- HTML形式で丸ごと保存 → 良さそう
ということで、記事間や外部へのリンクも残せるし、手軽な「HTML形式で丸ごと保存」でいくことに。ただブラウザで記事ページを一つ一つ表示させてHTML形式で保存するのはPDF保存と変わらないので、コマンドで1発で済ませよう。
そこで使用するコマンドが「wget」。
wgetコマンドとは
「wget」コマンドは、ウェブサーバーからコンテンツを取得するダウンロードツール。指定したURLのサイトを丸ごと保存できます。
wgetの準備
wgetはLinux系OSだとほぼ標準で利用可能で、MacやWindowsにも移植されてます。
Macにインストール
macOSはUnixベースのOSなのですが、wgetが標準では入っていません。ですのでHomebrewでインストールする必要があります。こちらもコマンド1発です。
$ brew install wgetWindowsにインストール
ゼロは普段Windowsをあまり使わないので、Windowsへのwgetのインストールはこちらをご参考に。
https://www.youfit.co.jp/archives/2230
https://pekochin.com/wget-windows/
Ubuntuには標準搭載!
特に必要な作業はありません。そのまま使えます。

必要なオプションはこれだけ
wgetコマンドにはたくさん指定できるオプションがあるのですが、特殊な使い方をしない限り(サイトのダウンロードだけを目的とするなら)、これだけおさえておけば問題ないはず。
| オプション | 意味 |
| -r –recurcive | 再帰ダウンロードを行う |
| -l 数 –level=数 | 再帰の深さ、リンクを辿る回数 -l 0 または -l inf は無限 |
| -p -–page-requisites | ローカル環境で表示するための必要な画像やスタイルシートなどのコンテンツも取得 |
| -k –convert-links | 取得したコンテンツ内のリンクをローカルを指すよう(相対パス)に書き換え |
| –restrict-file-names=nocontrol | マルチバイト文字のファイル名をダウンロードする場合の文字化け防止 *1 |
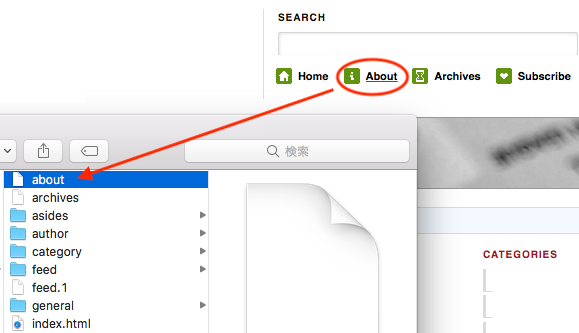
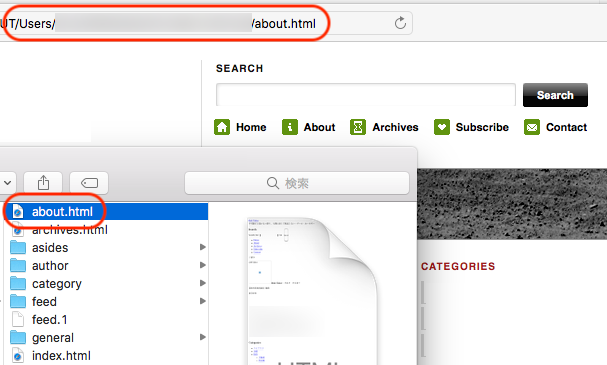
| –adjust-extension | 拡張子がついていないファイルに拡張子をつける。例えば、/aboutというHTMLはabout.htmlとして保存 *2 |
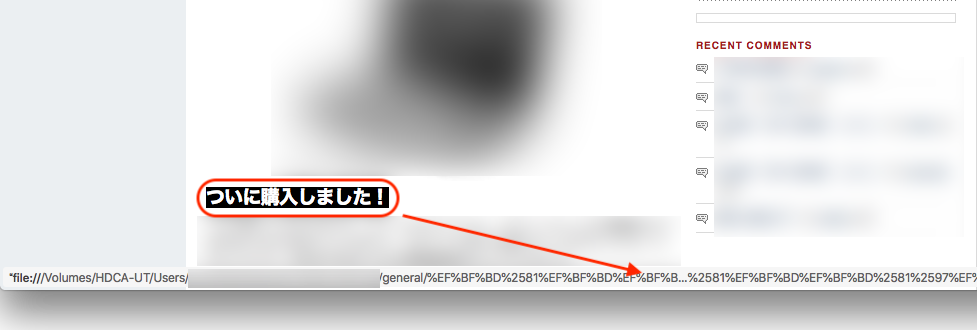
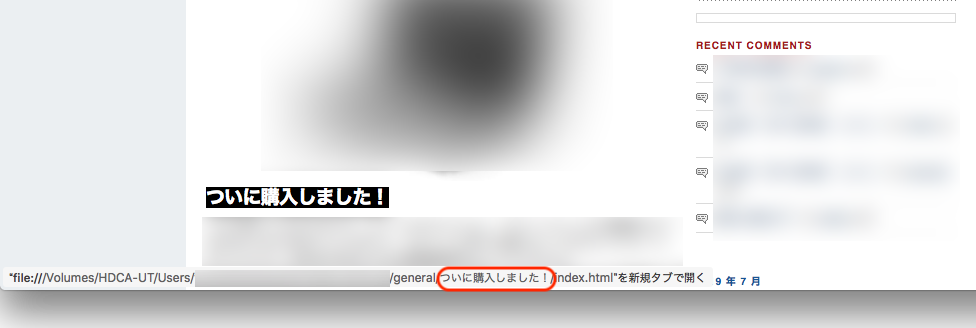
*1 日本語のリンク(URL)がある場合には
–restrict-file-names=nocontrol
日本語のURLがある場合、このオプションで文字化けを防げます。文字化けが発生するとリンクをクリックしてもそのページにジャンプしません。
*2 固定ページなどがHTMLファイルとして保存されない場合
–adjust-extension
リンクをクリックすると、WordPressではHTMLデータを返すので表示されるのですが、ダウンロードして保存するとファイルが.htmlファイルじゃなくてブラウザで開けないことがあります。そんな時のためのオプション。
まとめ:wgetコマンドはこれ
ごく一般的なサイトを丸ごとダウンロードするのに十分なコマンドはこれ。
wget -r -l 0 -p -k --restrict-file-names=nocontrol --adjust-extension <URL><URL>の部分をダウンロードしたいサイトのアドレスに置き換えて実行すれば保存されます。
-
前の記事

海外送金どうしてる?TransferWiseで安く賢く 2019.07.17
-
次の記事

またも手数料の違いにびっくり!TransferWise vs 街中銀行 2019.07.25